Import data from files
This lesson describes how to import files into tables. You can import data from XLS, XLSX and CSV files.
Open import dialog starting from datamodel view
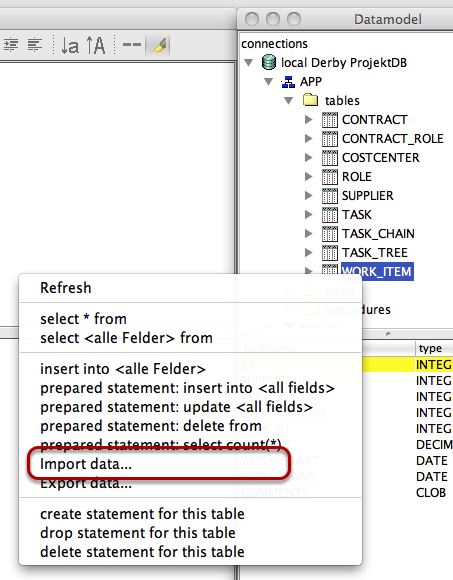
Open Datamodel and choose the table you want to import data by selecting "Import data..." from table context menu.
Configure import
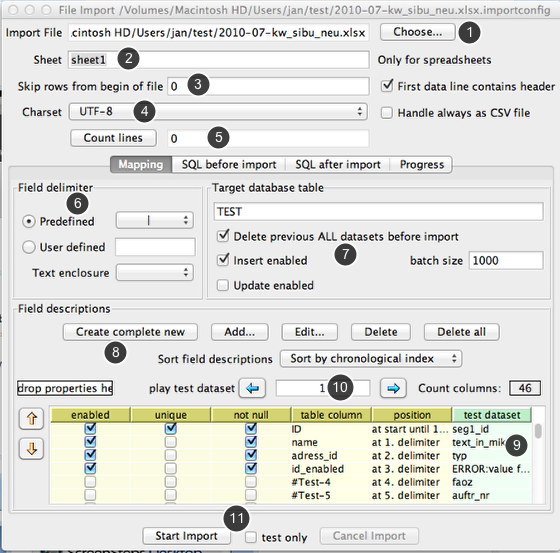
In the top area yo define the data source e.g. file name and sheet name (only if you import data from spreadsheets, leaf it blank to use the first sheet).
You can see a life preview what happens in your import, try to play test dataset. It doesn' t matter how large your file is, it will never loaded at once and shows immediatly a result.
The panel Field Delimiter is only used for text files, for spreadsheets this panel will be ignored.
The panel Target database table let you decide what to do with the new data. The batch size can only be filled and used for insert only imports.
The pane Field descriptions you define the mapping between the file contents and your table columns.
This table is drag&drop enabled. You can drag the table to any text editor and get the complete import description as text in form of properties.
You can drop a import description as text in the smal text area labeled with "Drop properties here".
1. Choose the data file
2. For spread sheets set the name of page
3. If necessary skip a couple of rows (this works for spreadsheets as well as for text files)
4. For text files choose the character set
5. Check the number of rows. For spreadsheets the last row is the first empty row! Unfortunatly all other counters are not reliable!
6. For text files define the column splitting method (only for delimiter seperated files, there are other options you can define for evere field)
7. Name and import method for the target database table
8. Define for every column the extraction method (double click in the table brings one field description)
9. examine test datasets
10. Jump to any line number within the data file (This works quick and fine also for very large files!)
11. Start the import (also as test without finally running any inserts, update or deletes, but with all parsing and reading)
Editing the import description for a particular column

The important things here are the datatype and the kind of positioning. An intersting feature is the aggregate values function. If the import does an update, a numeric values will added to the current value.
The feature "Ignore dataset if field is invalid" helps to keeps the logfile clean, if you know, that this field is acceptable malformed and you want to filter your import.
Use Locale for Date and Numeric formats to reflect different localized formats. E.g. in numeric fields the locale defines what char is to use as decimal delimiter.
If a field is empty you can take the content from an alternative field (That can lead in a cascade if the alternative field as an alternative field themself).
1. Enable this extraction (and usage of this field within inserts or updates)
2. Name of target database table column
3. Unique or not null check
4. If checks will be fail, should we continue with import?
5. Data type of field
6. For numbers: should value added to existing one
7. For date type, format of the text representation of date or time stamp
8. Locale for date or number types for better parsing (e.g. what char is the decimal point)
9. If the field is empty, should we take the content from an alternative field
10. Default value if field is empty
11. Extraction method for this field
12. Parameter for different extraction methods
13. Erase all spaces, tabs or lany other not visible chars from start and end of value
14. Use a regex expression to extract the final value from the former extracted text value (You can check this expression in the Regex tester in the tools menu)